Clustering
Clustering is an unsupervised learning approach that "clusters" data points based on the type of clustering technique. There are many varieties of clustering out there, such as hierarchical and k-means.
Different Types of Clustering
There is a remarkable diversity of clustering methods out there, with at least one scholar claiming that the reason for this is due to the vagueness of the term "cluster". In general, clustering algorithms group data in some way. How they accomplish this is incredibly varied. Here is a short list of different types of clustering algorithms:
-
k-Means
-
BIRCH
-
DBSCAN
-
OPTICS
-
Hierarchical
-
Expectation-Maximization (EM)
-
Subspace
-
Fuzzy
-
Biclustering
Partitional vs. Hierarchical
Clustering algorithms are commonly divided into partitional or hierarchical algorithms. Partitional clustering methods can be said to cluster on a flat partition, where each data point belongs to one and only one cluster. Hierarchical clustering methods create more than one layers of partitioning, where each cluster could have subclusters in it too.
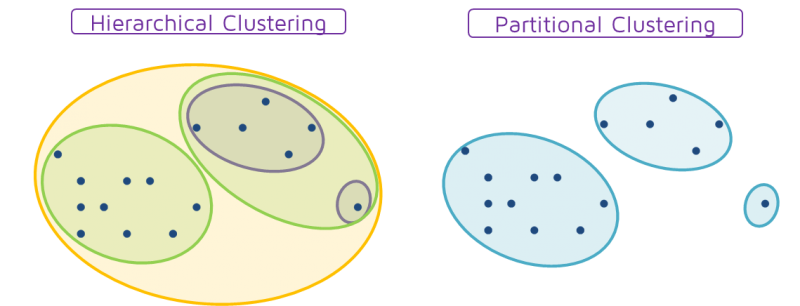
Hierarchical clustering methods:
-
Agglomerative: group data by larger and larger clusters
-
Divisive: group data by smaller and smaller clusters
Categories of Clustering Models
Below is a short list of categories of cluster modeling techniques:
-
Centroid-based clustering (like k-means)
-
Density-based clustering (like DBSCAN and OPTICS)
-
Distribution-based clustering (using statistical distributions like the multivariate normal to cluster)
-
Hierarchical clustering (also called connectivity models)
Code Examples
| All of the code examples are written in Python, unless otherwise noted. |
Containers
| These are code examples in the form of Jupyter notebooks running in a container that come with all the data, libraries, and code you’ll need to run it. Click here to learn why you should be using containers, along with how to do so. |
| Quickstart: Download Docker, then run the commands below in a terminal. |
k-Means Clustering
An implementation of k-Means Clustering to do an RFM marketing analysis.
#pull container, only needs to be run once
docker pull ghcr.io/thedatamine/starter-guides:k-means-clustering
#run container
docker run -p 8888:8888 -it ghcr.io/thedatamine/starter-guides:k-means-clusteringHierarchical Clustering
An implementation of (agglomerative) hierarchical clustering using national socioeconomic data.
#pull container, only needs to be run once
docker pull ghcr.io/thedatamine/starter-guides:hierarchical-clustering
#run container
docker run -p 8888:8888 -it ghcr.io/thedatamine/starter-guides:hierarchical-clusteringNeed help implementing any of this code? Feel free to reach out to datamine-help@purdue.edu and we can help!